Comparing projects
You can compare your project to any other project. For example, you can use this function to evaluate automatically produced annotations, e.g. your project, to manual annotations.
Using Browser GUI
- Go to your project page.
- top > projects > your_project
- If you are logged in, you will find the compare menu in the pane, Annotations

- Enter the name of an existing project, and click the button.
- After a while for computation, a link to comparison page will be shown in the compare menu.
Comparison Metric
In PubAnnotation, when a project is compared against another project, we call the former a study project and the latter a reference project. When the two projects include different sets of documents, only the documents shared by the two are considered, and the others are ignored.
For the set of shared documents, the set of annotations in the study project (called study annotations), \(A_S\), are compared against the set of annoations in the reference project (reference annotations), \(A_R\).
The number of true positives (TP), false positives (FP), and false negatives (FN) are counted as below:
\[TP = | A_S \cap A_R |\] \[FP = | A_S - A_R |\] \[FN = | A_R - A_S |\]The precision (P), recall (R), and F-score (F) are then calculated as below:
\[P = \frac{TP}{TP + FP}\] \[R = \frac{TP}{TP + FN}\] \[F = \frac{2PR}{P + R}\]Comparision of denotations
Denotations and relations are evaluated separetely.
For the set of shared documents between two projects, the set of study denotations, \(D_S\), is compared against the set of reference denotations, \(D_R\).
As explained in Format, a denotation is represented as a triple: < begin_offset, end_offset, label >.
Note that as a denotation is bound to a specific document, in fact, the character offsets, begin_offset and end_offset, should be prefixed with a document Id, e.g., docid:begin_offset, which is however omitted here for the sake of simplicity.
When we consider only exact matching between the study and reference denotations, comparison is performaed based on equibvalence, e.g., two denotations, \(d_1\) and \(d_2\) are equivalent to each other if and only if the three elements, begin_offset, end_offset, label, are the same between the two denotations. In the case, there is 1-to-1 correspondence between matching annotations.
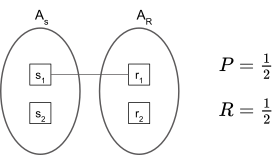
In the figure above, \(s_1\) matches to \(r_1\), making it a true positive. \(s_2\) is a false potive, and \(r_2\) is a false negative. In the case, computation of precision and recall is straightforward.
Sometimes, a soft matching scheme is desired over exact matching. For example, it is a common thought that exact span matching is a too much strict criterion for named entity recognition (NER), and evaluation of many NER tasks employs a sloppy span matching scheme: if there is a overlap between two spans, they are considered to match each other. However, such a soft matching scheme often yeilds a non 1-to-1 correspondence between matching annotations.
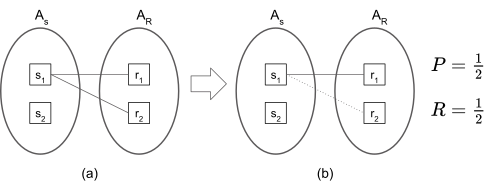
In (a) of the figure above, the annotation, \(s_1\), matches to two annotations, \(r_1\) and \(r_2\), e.g., the span of \(s_1\) includes the spans of both \(r_1\) and \(r_2\). In the case, the calulation of precision is still simple: one shot out of two has missed, so \(P = \frac{1}{2}\). Caluation of recall is however tricky: while all the two reference annotations have found their match, we do not want to say the recall is 100% because the study annotations have only one matching annotation. To simplify the calculation of recall, we set a rule: one shot can kill only one at most. According to the rule, the matching between \(s_1\) and \(r_2\) is deleted, in the notion that \(s_1\) is already consumed to kill \(r_1\), and cannot be reused for \(r_2\). Then, only 1-to-1 correspondence remains, and calculation of recall becomes simple (see (b) of the figure above).
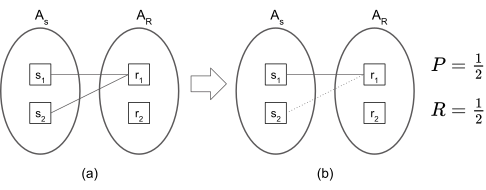
In (a) of the figure above, two annotations, \(s_1\) and \(s_2\), matches to one annotation, \(r_1\), e.g., the spans of \(s_1\) and \(s_2\) are included in the span of \(r_1\). In the case, the calulation of recall is simple: one shot out of two is missed, so \(R = \frac{1}{2}\). This time, caluation of precision is tricky: while all the two study annotations have found their match, we do not want to say the precision is 100% because only one reference annotation is shot. To simplify the calculation of precision, we set another rule: one shot is sufficient to kill one. According to the rule, the matching between \(s_2\) and \(r_1\) is deleted, in the notion that \(r_1\) is already killed by \(s_1\), and \(s_2\) is a redundant shot. Then, only 1-to-1 correspondence remains, and calculation of precision becomes simple (see (b) of the figure above).
Comparison of relations
For the set of shared documents between two projects, the set of study relations, \(R_S\), is compared against the set of reference relations, \(R_R\).
A relation is represented as a triple: < id_of_subject_denotation, predicate, id_of_object_denotation >. It means a relation is dependant on two denotations. In many cases, however, we cannot expect that the Ids of denotations to remain the same across \(R_S\) and \(R_R\). The Ids of denotations in a relation representation are thus replaced with the representations of denotations, e.g. < representation_of_subject_denotation, predicate, representation_of_object_denotation >, then the comparison becomes agnostic to the Ids. Note that the representation of a denotation is triple, and the representation of a relation becomes septuple after the id of a denoation is replaced to the representation.
Once id-agnostic representation of relations is acheived, comparison between \(R_S\) and \(R_R\) is performed exactly the same way as the comparision of denotations.
A non-1-to-1-correspondence issue is resolved exactly the same way as the comparison of denotations.